|
|
|
\require{AMSmath}



Aflezen grafieken
Beste medewerker,
voor mijn afstudeerscriptie heb ik een onderzoek gehouden onder 100 psychiatrische patienten naar hun mening over de aangeboden maaltijden binnen de instelling.
Ik heb alle resultaten in SPSS verwerkt, alleen heb ik nogal moeite met het trekken van conclusies.
Bijv: omdat ik wilde weten of er een verband was tussen de verblijfsduur van de patienten en hun mening over het eten, heb ik de verblijfsduur van alle patienten gemiddeld genomen en dit was gemiddeld 69 maanden. Ik heb alle patienten in twee categorien onderverdeeld, namelijk patienten die langer dan 69 maanden binnen de instelling verbleven en patienten die er korter dan 69 maanden verbleven. Ik heb deze twee groepen vergeleken met het gemiddelde cijfer dat ze voor de maaltijden gaven. Ik heb dit gedaan m.b.v. de independent sample T test en dit kwam eruit:
VR1.4 N Mean Std. Deviation Std. Error Mean
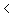 69 mnd 57 6,9739 1,34509 ,17816 69 mnd 57 6,9739 1,34509 ,17816
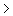 69 mnd 14 7,4956 1,15130 ,30770 69 mnd 14 7,4956 1,15130 ,30770
Wat kan ik hieruit nu eigenlijk concluderen? Omdat de standaard deviatie meer dan 0,05 is, kan ik nu zeggen dat de resultaten over deze vraag niet betrouwbaar zijn?
Kan ik met de independent sample T test wel conclusies trekken, of moet dit per se met de chi-kwadraat test.
Nog 1 laatste vraag: ik wil een heleboel verschillende groepen respondenten met elkaar vergelijken. Hoe kan ik dit het best doen?
Bij voorbaat vriendelijk bedankt
Jennifer
Jennif
Student hbo - maandag 22 november 2004
Antwoord
Op de eerste plaats heb je niet het volledig deel van de toets overgeplakt. Het meest belangrijke deel (met de berekende significance) ontbreekt. Daaruit trek je uiteidelijk je conclusies.
Daarnaast vind ik ook wel dat je een redelijk kleine steekproef hebt genomen. Waarom is me een raadsel, maar dit zal wellicht je onderzoek niet ten goede komen.
Nog kwalijker vind ik het volgende:
......omdat ik wilde weten of er een verband was tussen de verblijfsduur van de patienten en hun mening over het eten, heb ik de verblijfsduur van alle patienten gemiddeld genomen en dit was gemiddeld 69 maanden. Ik heb alle patienten in twee categorien onderverdeeld, namelijk patienten die langer dan 69 maanden binnen de instelling verbleven en patienten die er korter dan 69 maanden verbleven.
Ik bedoel de onderverdeling in de twee groepen aan de hand van de gemiddelde verblijfsduur. Deze verblijfsduur kent een zeer scheve verdeling dus een onderverdeling op basis van het gemiddelde heeft altijd het effect dat de rechtergroep veel kleiner wordt dan de linkergroep. Met zekerheid is de mediaan als grens dan een betere keus.
In jouw geval ligt de situatie echter nog wat anders: Gewenning aan de kwaliteit van het voedsel vindt na verwachting veel eerder plaats dan na 69 maanden. Dat betekent dat als er al een verschil in beoordeling van het eten is dat verschil wellicht al na een veel korter verblijf ontstaat. Daarnaast kan het best zo zijn dat de 14 personen die er al 69 maanden of meer zitten het allemaal ook niet zo interesseert. Je opzet geeft weinig hoop dat je hier iets zinnigs mee kunt doen.
Nu hangt het van de data af wat je uiteindelijk wel kan.
Ik raad je aan een spreidingsdiagram te maken met op de x-as de verblijfsduur en de y-as de waardering.
Dat spreidingsdiagram zou misschien informatie geven over het moment waarop een verandering in de beoordeling kan plaatsvinden (maar waarschijnlijk doet het dat niet).
Vervolgens zou ik niet twee maar minimaal drie ongeveer even grote groepen toetsen. bv een groep met een verblijfduur tot 12 maanden, een groep van 12 tot 36 maanden en een groep langer dan 36 maanden. Misschien moet je een andere indeling maken wanneer de aantallen binnen deze drie groepen heel erg ongelijk uitkomen.
Liefst had ik overigens nog wat meer groepen gehad (stuk of 4 a 5) maar dat zit er, gezien je geringe steekproefgrootte, niet helemaal in.
Gebruik dan als toets een variantieanalyse (anova-oneway) om verschillen aan te tonen en daarnaast een errorbargrafiek om de aantoonbare verschillen duidelijk te maken.
Met vriendelijke groet
JaDeX

|
Vragen naar aanleiding van dit antwoord? Klik rechts..!
zaterdag 27 november 2004
|

|



home |
vandaag |
bijzonder |
gastenboek |
statistieken |
wie is wie? |
verhalen |
colofon
©2001-2024 WisFaq - versie 3
|
